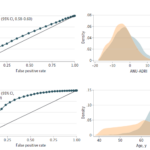
2023-06-24 / 最終更新日時 : 2023-06-24 山本陵平 cjc/djc 2023年6月28日 cjc 認知症予測スコアによる認知症予測能 2023年6月28日のclinical journal clubでは、2023年6月13日にJAMA Network Open (IF 13.3)に掲載された、4種類の認知症スコアの認知症予測能を評価したUK Bioba […]
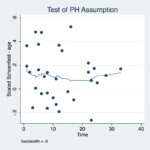
2021-11-26 / 最終更新日時 : 2021-12-13 山本陵平 stata Stata: Cox比例ハザードモデル Stataを用いて、Kaplan-Meier曲線を作成し、多変量Cox比例ハザードモデルを作成してみましょう。 今回は、サンプルデータCancer Drug Trialを利用します。 Cancer Drug Trialデ […]
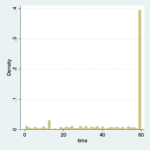
2021-11-26 / 最終更新日時 : 2021-11-26 山本陵平 stata Stata: discrete time hazard model 追跡期間が、連続変数ではなく、カテゴリ変数(1-2ヶ月、3-6ヶ月、7-12ヶ月等)である場合、通常のCox比例ハザードモデルではなく、discrete time hazard modelを用いた方がよい場合があります。 […]
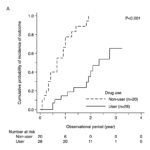
2021-11-25 / 最終更新日時 : 2021-11-27 山本陵平 stata Stata: Kaplan-Meir曲線 Stataの特徴は比較的簡単に美しいグラフの作成できることです。Stataのサンプルデータdrug2を使って、Kaplan-Meier曲線(白黒)を作成してみましょう。 このKaplan-Meier曲線に設定を追加して、 […]