2024-06-24 / 最終更新日時 : 2024-08-11 山本陵平 impact factor Impact Factor 2023 過去のImpact Facotor 2021, 2022 一般 98.4 Lancet 96.2 New England Journal of Medicine 93.6 BMJ 63.1 JAMA 22.5 JAMA […]
2024-02-10 / 最終更新日時 : 2024-02-10 山本陵平 cjc/djc 2024年2月21日Clinical Journal Club 2024年2月21日のcjcは、UK Biobankコホートの痛風の既往を有する患者において、尿酸値と痛風の再発の関連を評価した生存解析を取り上げます。典型的なコホート研究の論文の書き方を学びます。 https://do […]
2023-08-08 / 最終更新日時 : 2023-08-08 山本陵平 cjc/djc 2023年8月9日 cjc カフサイズと血圧 2023年8月9日のClinical Journal Clubは、JAMA Internal Medicine (Impact Factor 39.0)に掲載された、適切なサイズと不適切なサイズのカフで測定された血圧の差 […]
2023-07-10 / 最終更新日時 : 2023-07-14 山本陵平 cjc/djc 2023年7月28日 djc AI搭載型 2023年7月26日のDigital health Journal Clubは、JMIR mHealth and uHealth (Impact Factor 5.0)に掲載されたAI搭載型腎臓病教育アプリ+看護師による […]
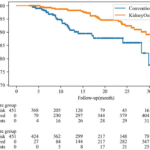
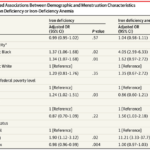
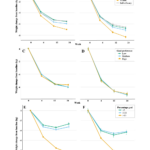
2023-07-10 / 最終更新日時 : 2023-08-01 山本陵平 cjc/djc 2023年8月2日 cjc 若年女性の鉄欠乏・鉄欠乏性貧血の有病率 2023年8月2日のclinical journal clubでは、2023年6月27日にJAMA (IF 120.1)にレターとして掲載された米国国民健康栄養調査(National Health and Nutriti […]
2023-07-10 / 最終更新日時 : 2023-07-10 山本陵平 cjc/djc 2023年7月21日 djc 米国におけるウェアラブル機器の利用率 2023年7月21日のclinical journal clubでは、2022年6月7日にJAMA Netwok Open (IF 13.8)に掲載された、米国人9303人において、ウェアラブル機器の利用者の特徴を明らか […]
2023-07-10 / 最終更新日時 : 2023-07-14 山本陵平 cjc/djc 2023年7月14日 djc アプリ利用開始時の減量目標とその後の体重変化 2023年7月14日のclinical journal clubでは、2022年10月28日にJournal of Medical Internet Research (IF 7.4)に掲載された、食事・運動習慣の改善ア […]
2023-07-09 / 最終更新日時 : 2023-07-09 山本陵平 cjc/djc 2023年7月19日 cjc 入眠障害と全死亡 2023年7月19日のclinical journal clubでは、2023年6月にJAMA Healthy Longevity (IF 13.1)に掲載されたKorean Genome and Epidemiolog […]
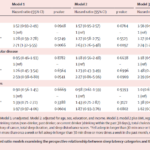
2023-07-09 / 最終更新日時 : 2023-07-09 山本陵平 cjc/djc 2023年7月12日 cjc 高齢患者におけるGeriatric 8のアウトカム予測 2023年7月12日のclinical journal clubでは、2023年6月13日にJAMA Healthy Longevity (IF 13.1)に掲載された、新規診断された高齢癌患者6391人において、健康状 […]
2023-07-07 / 最終更新日時 : 2024-06-24 山本陵平 impact factor Impact Factor 2022 一般系 デジタル系 腎臓系 老年系 睡眠系 歯科系 栄養系 喫煙・飲酒系 Impact Factor 2021, 2023 一般系 168.9 Lancet 158.6 New England Journal of Me […]